

Dziękujemy za wypełnienie formularza kontaktowego!
Twoja wiadomość już do nas leci - napiszemy bądź zadzwonimy do Ciebie tak szybko, jak to możliwe.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:


I fru... Twoja wiadomość już leci na nasze skrzynki!
Zajrzyj na swoją pocztę, aby poznać szczegóły oferty ;)
Tymczasem, sprawdź nowości na naszym blogu semahead.agency/blog/
Zespół Semahead by WeNet
Dziękujemy za zapis do Newslettera!
Na Twoją skrzynkę wysłaliśmy wiadomość potwierdzającą subskrypcję.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:
'
Dziękujemy za wypełnienie formularza zgłoszeniowego!
Twój formularz już do nas leci - za chwilę otrzymasz informację zwrotną na podany w zgłoszeniu email.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, możesz zajrzeć na nasze social media:

Dla każdego właściciela strony internetowej ważne jest, aby jego domena pojawiała się jak najwyżej w wynikach wyszukiwania. Czasami, pomimo dobrych chęci, może pojawić się błąd, który spowoduje zanik jej widoczności. W skrajnych przypadkach nasza strona może stać się całkowicie niewidzialna dla Google. Jakich błędów unikać przy wprowadzaniu zmian w serwisie, aby nie dopuścić do takiej sytuacji? Poniżej opisałem 5 błędów, których nie warto popełniać.
Noindex jest jedną z możliwych wartości meta tagu „robots”. Domyślnymi wartościami tego tagu są „index” i „follow”. Wartość „index” informuje robota Google, że dana podstrona może zostać przez niego zaindeksowana, dzięki czemu będzie widoczna w wynikach wyszukiwania Google. Natomiast wartość „follow” to informacja dla robota o tym, że może podążać za linkami na danej podstronie. Meta tag „robots” z domyślnymi wartościami wygląda następująco:
<meta name=”robots” content=”index, follow”>
Znaczniki te powinny znajdować się na wszystkich podstronach, które mają być zaindeksowane w wynikach wyszukiwania Google. Instrukcja ma za zadanie pomóc robotowi Google w indeksacji serwisu w przypadku, gdyby wystąpiły problemy podczas indeksowania.
W serwisie mogą wystąpić strony, których nie chcemy zaideksować w Google (np. strony powstałe w wyniku sortowania, czy też filtracji) – wówczas korzystamy z wartości „noindex” meta tagu „robots”. Taka strona nie jest indeksowana przez robota Google, przez co jest niewidoczna w Google.
Niewłaściwie użyjcie wartości „noindex” może spowodować spadki widoczności serwisu. Dla przykładu: dzieje się tak wówczas, gdy wdrożymy wartość na stronach kategorii, podkategorii lub produktów. Natomiast gdy wartość „noindex” wdrożymy na wszystkich podstronach serwisu (przez przypadek czy też celowo) witryna stanie się niewidoczna w wynikach wyszukiwania Google, ponieważ zostanie wyindeksowana.

Plik robots.txt ma za zadanie zdefiniować, które obszary witryny powinny zostać zablokowane przed dostępem robotów. Podstawowym błędem, który może wystąpić przy tworzeniu pliku robots.txt, jest zablokowanie robotom dostępu do witryny. Podstawowy plik robots.txt może zawierać instrukcje:
User-agent: *
Allow: /
User-agent: * – oznacza, że dyrektywa odnosi się do robotów wszystkich wyszukiwarek internetowych, a nie tylko do robota Google.
Allow:/ – oznacza zezwolenie na indeksacje całej witryny.
Jeżeli zrobimy błąd, czyli zamiast „allow” wpiszemy „disallow”:
User-agent: *
Disallow: /
W takim przypadku zamiast dać robotom dostęp do wszystkich zasobów strony, uniemożliwiamy im to. Roboty nie będą miały dostępu do zawartości strony, przez co witryna nie będzie mogła być zaindeksowana i widoczna w wynikach wyszukiwania Google.
Przykładowo, po wdrożeniu certyfikatu SSL, powinniśmy zadbać, aby serwis w wynikach wyszukiwania był dostępny jedynie pod jednym adresem. W tym celu wybieramy wersje z www lub bez www i wszystkie pozostałe przekierowujemy za pomocą przekierowania „301” na wybraną przez nas wersję. Jeżeli wszystko wykonamy poprawnie, możemy cieszyć się z efektu naszej pracy. A co, jeśli popełnimy błąd we wdrożeniu przekierowań w pliku .htaccess?
Przez przypadek możemy wówczas stworzyć tzw. pętlę przekierowań. Dla przykładu podstrona z www będzie przekierowywać na podstronę bez www, a strona bez www na stronę z www (podobnie może być z http i https). W tej sytuacji robot Google nie będzie w stanie dostać się na naszą stronę i nie zaindeksuje jej. Przez błędnie wykonane przekierowania w pliku .htaccess możemy stać się niedostępni dla niego.
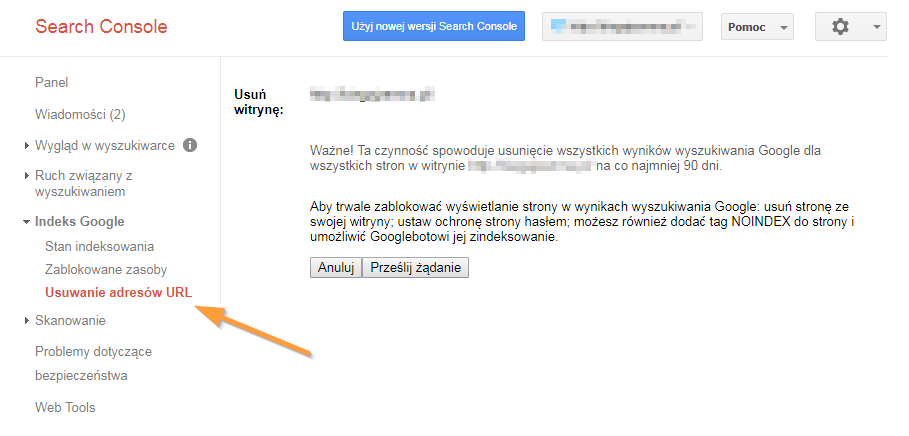
Zapewne większość z was korzysta z narzędzia Google Search Console do analizy błędów na stronie czy też poprawnej indeksacji serwisu. Narzędziem tym można również tymczasowo (na maksymalnie 90 dni) usunąć swoje adresy URL z wyników wyszukiwania. Jeżeli została zaindeksowana podstrona, której nie chcieliśmy indeksować, możemy w szybki sposób usunąć ją z wyników wyszukiwania. Jeżeli jednak zamiast konkretnej podstrony wpiszemy adres strony głównej, Google Search Console wyindeksuje nam nie tylko stronę główną, ale również wszystkie podstrony w witrynie. Przez maksymalnie 90 dni staniemy się niewidzialni w Google – chyba, że anulujemy zgłoszoną prośbę o wyindeksowanie.
Może również zdarzyć się tak, że zależy nam na bardzo szybkich efektach i uzyskaniu wysokich pozycji w wyszukiwarce Google w jak najkrótszym czasie. Wtedy możemy wykorzystać metody, które mają na celu „oszukać” wyszukiwarki. W momencie, kiedy Google zauważy, że dana strona internetowa stosuje zabronione praktyki, może nałożyć na stronę filtr, który powoduje spadki pozycji w wyszukiwarce o kilkadziesiąt pozycji. W przypadku, kiedy rażąco naruszymy wytyczne Google, możemy otrzymać za to ban, który skutkuje całkowitym usunięciem strony z wyników wyszukiwania. Ban nakładany jest bardzo rzadko i nie jest wynikiem spamowych linków przychodzących czy też czynników zewnętrznych, na które właściciel witryny nie ma wpływu. Przez swoje świadome lub nieświadome działanie możemy gwałtownie utracić pozycję w wyszukiwarce Google i po prostu stać się niewidzialni.
Proces optymalizacji i pozycjonowania strony jest procesem złożonym, który wymaga dużej wiedzy i nadzoru nad wprowadzanymi zmianami. Czasami przez mały błąd lub niepoprawne działania jesteśmy w stanie stać się niewidzialni dla Google. Trzeba być uważnym, aby nie popełniać wyżej wymienionych błędów, ponieważ cała nasza praca nad serwisem może pójść na marne.
Na szczęście większość opisanych błędów jesteśmy w stanie bardzo szybko naprawić. Dzięki wprowadzanym działaniom naprawczym w krótszej lub dłuższej perspektywie widoczność serwisu w Google powróci do podobnego poziomu sprzed wyindeksowania. Czas ten zależy od tego, jak długo nasza domena przebywała poza indeksem Google.


Chcesz zacząć współpracę z nami? Wypełnij formularz!
Wypełnienie zajmie Ci kilka chwil a nam pozwoli
lepiej przygotować się do rozmowy z Tobą.
