

Dziękujemy za wypełnienie formularza kontaktowego!
Twoja wiadomość już do nas leci - napiszemy bądź zadzwonimy do Ciebie tak szybko, jak to możliwe.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:


I fru... Twoja wiadomość już leci na nasze skrzynki!
Zajrzyj na swoją pocztę, aby poznać szczegóły oferty ;)
Tymczasem, sprawdź nowości na naszym blogu semahead.agency/blog/
Zespół Semahead by WeNet
Dziękujemy za zapis do Newslettera!
Na Twoją skrzynkę wysłaliśmy wiadomość potwierdzającą subskrypcję.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:
'
Dziękujemy za wypełnienie formularza zgłoszeniowego!
Twój formularz już do nas leci - za chwilę otrzymasz informację zwrotną na podany w zgłoszeniu email.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, możesz zajrzeć na nasze social media:

Witryny internetowe w wyszukiwarce Google wyświetlane są w oparciu o stosowny ranking – to do najwyższych pozycji domeny w tymże rankingu dążą specjaliści SEO wdrażając optymalizacje i działania pozycjonujące. Co jednak musi się wydarzyć, aby Twoja witryna w ogóle miała szansę znaleźć się w rankingu wyszukiwarki?
Z tego artykułu dowiesz się m.in.:

Wyszukiwarka giganta z Mountain View to bardzo zaawansowane technologicznie rozwiązanie, które już dawno wykroczyło poza podstawową definicję wyszukiwarki internetowej. Mimo tego, możemy wyróżnić jej trzy, podstawowe funkcje:
a) Crawlowanie – przeszukiwanie zasobów Internetu i przeglądanie ich pod kątem zawartości.
b) Indeksację adresów – przechowywanie i organizację adresów URL odnalezionych podczas crawlowania.
c) Tworzenie rankingu witryn – ustalenie kolejności wyświetlania adresów w wyszukiwarce na podstawie określonych czynników rankingowych.

Większość artykułów w sieci dotyczących pozycjonowania koncentruje się jedynie na ostatniej z przedstawionych powyżej funkcji. Tymczasem, aby strona została wyświetlona w wynikach wyszukiwania – konieczne jest, aby mechanizmy wyszukiwarki najpierw ją odnalazły, skategoryzowały na podstawie zawartości oraz umieściły w stosownym zbiorze danych – indeksie. Umieszczenie jej w rankingu i wyświetlenie w wynikach wyszukiwania jest ostatnim etapem całego procesu.
Szacuje się, że w Internecie jest co najmniej 5.5 biliona zaindeksowanych stron, a to nie wszystko – pamiętajmy, że Google wykorzystuje informacje pochodzące nie tylko z witryn, ale także zawartości tworzonej przez użytkowników (np. opinii), zeskanowanych książek, czy publicznych baz danych dostępnych w sieci. To sprawia, że odkrycie Twojej strony internetowej nie jest tak prozaiczne jak mogłoby się wydawać.
Jak przekazuje samo Google – „Proces określania, które wyniki wyświetlić, zaczyna się na długo przed wpisaniem zapytania(…)”. Aby skutecznie promować swoją witrynę, warto zwrócić zatem szczególną uwagę na te dwa aspekty działania wyszukiwarki.
Zacznijmy więc od omówienia pierwszego kontaktu Google z Twoją witryną podczas procesu crawlowania.

Crawl witryny to proces inicjowany przez wyszukiwarkę, który odpowiada za przeszukiwanie zasobów sieci i określanie ich zawartości. Za crawlowanie odpowiadają roboty (ang. robots), zwane także pająkami (ang. web spiders), ze względu na sposób ich działania – najczęściej podążają bowiem za linkami obecnymi w treści, tworząc niejako pajęczynę połączeń pomiędzy zasobami.

Google do crawlowania stron wykorzystuje kilkanaście różnych robotów, niemniej jednak w kontekście pozycjonowania stron WWW należy skupić się na dwóch z nich: Googlebotowi w wersji na urządzenia stacjonarne i jego młodszym bracie – Googlebotowi w wersji na urządzenia mobilne.

Warto zwrócić uwagę, że zasobami crawlowanymi przez roboty mogą być nie tylko całe strony internetowe, ale i dokumenty .pdf, pliki graficzne czy filmy. Aby robot Google przeprowadził crawl strony – wyszukiwarka musi mieć świadomość jej istnienia. W związku z tym, iż nie istnieje globalny spis stron internetowych, Google może dowiedzieć się o konkretnej stronie na dwa sposoby:
a) Do strony prowadzą linki na innych stronach, które już znajdują się w indeksie Google i roboty mogą za nimi podążyć.
b) Właściciel witryny zgłosił w mapie witryny przekazanej w Google Search Console dany adres internetowy.
Robot odwiedza dany adres URL i sprawdza jego zawartość – crawluje go. Na tym etapie pobierana jest jedynie część zasobów witryny. Następnie, dzięki wykorzystaniu Web Rendering Services (tzw. WRS) strona jest renderowana – uruchamiany jest jej kod, oceniana zawartość i treść, struktura oraz layout. Komponent WRS analizuje i identyfikuje zasoby, które nie są dostępne dla Googlebota podczas wstępnego crawla i przesyła do niego informację o nich.
Więcej na temat problemów z renderowaniem zasobów oraz samego WRS znajdziesz w Naszym artykule „Jak najlepiej wykorzystać kod JavaScript w SEO?”.
Jeżeli chcesz poszerzyć swoją wiedzę o tym w jaki Google renderuje Twoją witrynę, sprawdź artykuł „Google Shares Details About the Technology Behind Googlebot”, w którym w skondensowany sposób zebrane zostały informacje dot. wypowiedzi jednego z pracowników Google z 2017 roku na temat technologii, jaką wykorzystuje Googlebot.
Wszystkie znane Google adresy dodawane są do indeksu o kodowej nazwie Caffeine, o którym opowiemy w dalszej części tego artykułu.

Poruszając temat crawlowania, nie można nie wspomnieć o kwestii ściśle powiązanej – tzw. crawl budget, czyli budżecie crawlowania.
Crawl budget to liczba stron witryny, która może być crawlowana przez roboty Google danego dnia. Jeżeli liczba ta przekracza budżet crawlowania – niektóre podstrony mogą nie zostać dodane do indeksu Google.
Ograniczenie to wprowadzone zostało przez Google z dwóch powodów:
1. Zbyt intensywny crawl zasobów witryny mógłby spowodować przeciążenie serwera, a co za tym idzie problemy ze stabilnością i prędkością danej witryny – Crawl Rate Limit.
2. Nawet taki kolos jak Google nie posiada wystarczających zasobów, aby crawlować wszystkie strony dostępne w Internecie równolegle. Nie wszystkie strony również muszą być crawlowane – Crawl Demand.

Odpowiedź w tym przypadku jest szalenie prosta – strona, na której Googlebot nie przeprowadził crawla nie zostanie dodana do indeksu, a zatem – nie będzie również miała szansy wyświetlić się w wynikach wyszukiwania na zapytanie użytkownika.
Temat Crawl Budget poruszymy szerzej w innym artykule, gdyż zasługuje on na pełnoprawne, wyczerpujące objaśnienie.
Skoro wyjaśniliśmy już kwestię crawlowania, to czas na kolejny etap – indeksację.
Indeksem wyszukiwarki nazywamy zbiór ustrukturyzowanych danych dot. witryn i adresów URL, które zostały poddane procesowi crawlowania przez roboty.
Co to oznacza w praktyce?
W indeksie Google przechowywane są wszystkie dane, które udało się pozyskać Googlebotom podczas crawli. Dane te będą mogły zostać wykorzystane do utworzenia rankingu na podstawie określonych przez wyszukiwarkę czynników rankingowych – jakości treści, mocy linków przychodzących, stanu optymalizacji technicznej i wielu innych.
W momencie wpisania frazy lub zapytania przez użytkownika do wyszukiwarki – z indeksu pobrane zostaną tylko najbardziej odpowiednie wyniki i ułożone w kolejności – od najbardziej istotnych wg. algorytmów rankingujących.
Według aktualnych danych liczba stron zaindeksowanych w Google w ciągu ostatnich 3 lat wzrosła o około 20 bilionów, a ostatnia, duża zmiana związana z procesem indeksacji stron w wyszukiwarce z Kaliforni została wprowadzona w czerwcu 2010 roku, kiedy to ogłoszono, iż Google korzystać będzie z nowego systemu o nazwie Caffeine: https://webmasters.googleblog.com/2010/06/our-new-search-index-caffeine.html
Caffeine pozwala na indeksację zasobów w mniejszych partiach, co sprawia, iż aktualizacje indeksu mogą odbywać się na bieżąco i w teorii strony do niego zgłoszone mogą pojawiać się szybciej w wynikach wyszukiwania.
Przy tak ogromnej liczbie danych nie ma jednak możliwości, aby zawsze były one poprawne. Ostatnie doniesienia branżowe pokazują, że Google coraz częściej ma problemy z indeksacją stron. Warto zatem uważnie obserwować stan indeksacji swojej witryny przy użyciu Google Search Console.
Raport dostępny w zakładce Stan > Prawidłowy wskazuje ile dokładnie podstron Twojej domeny znajduje się w indeksie Google:
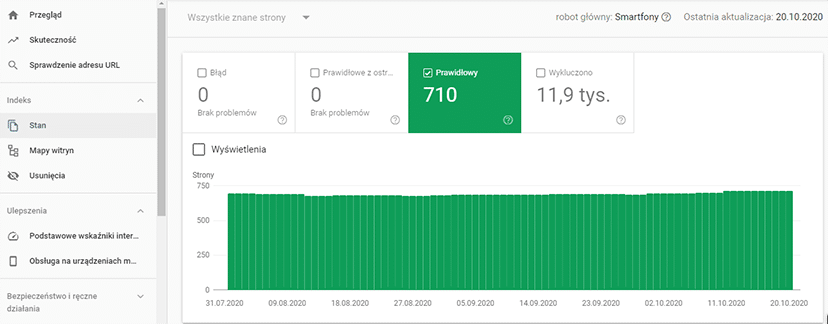
Należałoby kontrolować cyklicznie, czy na liście znajdują się wszystkie adresy, które faktycznie powinny być obecne w indeksie – poprawne, nie zgłaszające błędów, nie oznaczone jako te, które zaindeksowane być nie powinny.
Przestrzec należy jednak przed używaniem do analizy indeksacji operatora wyszukiwania site:
W wielu przypadkach wyszukiwarka poprawnie zwróci konkretny, zaindeksowany adres po wykorzystaniu zapytania typu site:domena.pl/katalog/strona, jednak trzeba pamiętać, że wyniki wyszukiwania nie są indeksem Google! Jedyna, pewna informacja o tym czy adres znajduje się w indeksie Google pochodzi zawsze z Google Search Console.
To właśnie ten fakt powoduje, że tak istotna jest wiedza na temat sposobu crawlowania i indeksacji wyników przez Google. Im większa witryna, tym większą uwagę należy zwrócić na to w jaki sposób Googlebot ją crawluje i czy indeksacja przebiega poprawnie.
Istnieje wiele metod wspomagania indeksacji i zarządzania budżetem crawlowania, o którym tutaj wspomnieliśmy, jednak jest to na tyle rozległy temat, iż należałoby poświęcić mu osobną publikację.
Będąc użytkownikami wyszukiwarki często zapominamy o tym ile rzeczy musi wydarzyć się zanim Google odpowie nam np. na pytanie gdzie napijemy się najlepszej kawy w Krakowie. Przełóżmy więc tę wiedzę na biznes!
Znalezienie się Twojej witryny w indeksie Google to dopiero początek długiej drogi zwanej pozycjonowaniem, jest to jednak początek kluczowy. Chcesz działać na większą skalę i zwiększyć swoje zyski? Skontaktuj się z nami!



Chcesz zacząć współpracę z nami? Wypełnij formularz!
Wypełnienie zajmie Ci kilka chwil a nam pozwoli
lepiej przygotować się do rozmowy z Tobą.
