

Dziękujemy za wypełnienie formularza kontaktowego!
Twoja wiadomość już do nas leci - napiszemy bądź zadzwonimy do Ciebie tak szybko, jak to możliwe.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:


I fru... Twoja wiadomość już leci na nasze skrzynki!
Zajrzyj na swoją pocztę, aby poznać szczegóły oferty ;)
Tymczasem, sprawdź nowości na naszym blogu semahead.agency/blog/
Zespół Semahead by WeNet
Dziękujemy za zapis do Newslettera!
Na Twoją skrzynkę wysłaliśmy wiadomość potwierdzającą subskrypcję.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:
'
Dziękujemy za wypełnienie formularza zgłoszeniowego!
Twój formularz już do nas leci - za chwilę otrzymasz informację zwrotną na podany w zgłoszeniu email.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, możesz zajrzeć na nasze social media:

W 2019 roku trudno wyobrazić sobie stronę internetową bez zalet, oferowanych przez JavaScript. Dzięki niemu witryna nabiera interaktywności oraz atrakcyjności wizualnej. Obok wielu zalet niestety mogą pojawić się także wady. Nieumiejętne jego użycie może prowadzić na przykład do pogorszenia prędkości ładowania strony. Jak wykorzystać kod JavaScript w SEO? Jak sprawdzić poprawność jego wdrożenia? To tylko dwa pytania, na które odpowiedź znajdziesz poniżej.
JavaScript jest skryptowym językiem programowania, który umożliwia interakcje użytkownika z witryną. Jego użycie dynamiczne zmiany na stronie, np. dotyczące jej wyglądu lub sposobu wyświetlania treści.
Używając JS na stronach opartych o kod HTML, wykorzystujemy tzw. DOM, czyli Obiektowy Model Dokumentu. To sposób w jaki opisywany jest dokument HTML poprzez elementy uporządkowane w hierarchicznej strukturze drzewa. Innymi słowy przeglądarka pobierając kod źródłowy HTML z serwera, nadaje mu odpowiednią strukturę drzewa DOM. Następnie wykorzystując JavaScript możemy dowolnie zmieniać jego konkretne elementy.
Przykładowo: po kliknięciu przycisku umieszczonego w danym miejscu, w konkretnym znaczniku HTML (np.<span>) zostanie wykonana akcja polegająca na pojawieniu się nowego tekstu na danej podstronie. Dzięki JavaScript możliwe jest dokonywanie zmian na danej podstronie bez potrzeby ponownego jej przeładowywania (odświeżania). Dzieje się tak dlatego, ponieważ bazujemy na już wcześniej pobranym z serwera dokumencie HTML.
Jeszcze kilka lat temu roboty Google interpretując stronę internetową całkowicie ignorowały kod JavaScript. Przełom nastąpił w 2014 roku. Firma ogłosiła wówczas, że posiada zasoby pozwalające na lepsze zrozumienie nowoczesnych stron www oraz renderowanie kodu JS, co w konsekwencji wpłynęło na wyniki wyszukiwania.
Pobieranie i renderowanie kodu JS było i nadal jest dla Google dosyć czasochłonne. Ze względu na te ograniczenia interpretacja JavaScript przez odpowiednią usługę wyszukiwarki nie była pełna. Oczywiście potentat z Doliny Krzemowej stale usprawnia swoje algorytmy. Dzięki temu w maju 2019 ogłosił, że Googlebot będzie aktualizowany tak często jak przeglądarka Chrome, co w uproszczeniu oznacza obsługę nowych funkcji w niej zawartych. To z kolei umożliwia dostrzeżenie nowych treści przez robota, które wcześniej mogły być dla niego niedostępne.
Co istotne, jeszcze do niedawna do renderowania witryn Google używało mechanizmów opartych na wersji 41 Google Chrome. Obecnie wszystko realizowane jest w ramach jej najnowszej wersji (w trakcie pisania tego artykułu jest to wersja 74). Warto dodać, że zarówno starsza wersja 41 jak i najnowsza nie używają wszystkich funkcji silnika Chrome. Nadal więc pewne elementy nie są obsługiwane.

Dla lepszego zrozumienia dalszej części artykułu w uproszczeniu opiszę teraz działania robotów wyszukiwarki na stronie oraz sposób ich renderowania i analizowania przez algorytmy.
1. Googlebot (crawler Google) na początku wykorzystując domyślne ustawienia, odwiedza daną witrynę z zamiarem pobrania z niej odpowiednich danych.
2. Po odwiedzeniu kolejnych podstron oraz pobraniu z nich zawartości w postaci kodu HTML oraz CSS Googlebot przesyła zebrane dane do odpowiednich usług Google. Są one odpowiedzialne za interpretowanie tego, co otrzymują. Jeśli na stronie nie ma kodu JavaScript indexer Caffeine bardzo szybko indeksuje stronę.
Jeśli natomiast na stronie znajdują się pliki JS, indeksowanie pełnej zawartości strony trwa dłużej, ponieważ Google musi pobierać dane, przesłać je dalej oraz muszą one być zinterpretowane przez odpowiednią usługę.
Za renderowanie strony odpowiada usługa WRS (Web Rendering Service), która po przetworzeniu danych przesyła je do odpowiednich algorytmów oraz niektóre z nich z powrotem do Googlebota. Otrzymuje on głównie informacje o linkach z danej podstrony, do których nie mógł się dostać z uwagi na potrzebę renderowania JS.
Google w 2018 roku oficjalnie ogłosił też, że renderowanie witryn obsługiwanych przez JavaScript w wyszukiwarce Google bywa odroczone do czasu, gdy WRS będzie dysponował odpowiednimi zasobami do przetwarzania tej treści.
Warto w tym kontekście wspomnieć, że jeśli zależy nam na sprawnym crawlowaniu witryny przez roboty, to bardzo ważne jest używanie linków wewnętrznych umieszczonych w znacznikach, które nie utrudniają „chodzenia po serwisie” robotom, ponieważ nie muszą one czekać na wyeksportowanie linków z kodu JS przez usługę WRS.
Poniżej znajduje się grafika, którą przedsiębiorstwo z Mountain View zaprezentowało podczas Google I/O w 2018 roku. Przedstawia ścieżkę od pobrania do indeksacji strony.
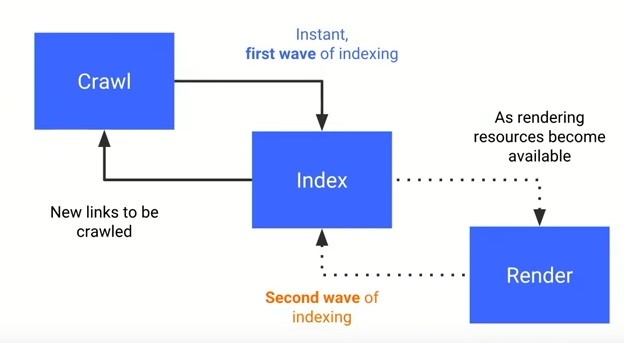
3. Po otrzymaniu pełnej zawartości strony, algorytmy wyszukiwarki za pośrednictwem odpowiednich mechanizmów decydują o całkowitym indeksowaniu oraz ustalaniu pozycji danej podstrony w wyszukiwarce.
Jak widać, crawlowanie strony i ustalanie jej pozycji w wyszukiwarce to złożone działania, które potrzebują odpowiednio dużych zasobów mocy obliczeniowej. Dlatego z kolei (nawiązując głównie do kontekstu tego artykułu) tak ważne jest, aby kod JavaScript nie wpływał na podstawowe pobranie zawartości HTML i nie utrudniał interpretacji kodu przez algorytmy wyszukiwarek.
Jeśli nie blokujemy robotom dostępu do plików JS wówczas Google powinien renderować drzewo DOM w taki sposób, jak robi to odpowiednia wersja przeglądarki Chrome. Jak jednak wcześniej wspomniałem, nadal istnieją elementy, których usługa WRS nie obsługuje. Można się domyślić, że jest to więc zależne od używanych przez systemy CMS oraz programistów technologii.
Użyty na stronie rodzaj oraz wersja frameworka języka JavaScript są z kolei istotne w kontekście wspierania danego sposobu, w jaki witryna jest renderowana (SSR, CSR, Hybrid Rendering, Prerendering). Wspomnę jeszcze o tym nieco później.
W celu sprawdzenia funkcjonalności kodu naszej strony, wyszukiwania potencjalnych błędów oraz utrudnień dla Google możemy użyć różnych rozwiązań opisanych poniżej. Większość z nich nie stanowi jednak sposobu na dokładne sprawdzenie tego, jak Google tak naprawdę „widzi” naszą witrynę. Na samym początku napiszę jednak, dlaczego do badania poprawności renderowania JavaScript przez Google nie warto korzystać z użycia komendy cache.
Aby sprawdzić zawartość pamięci podręcznej Google na temat danej podstrony należy użyć komendy cache: przed adresem URL danej podstrony w pasku przeglądarki, na przykład:
cache:http://przykladowadomena.pl/adres
Otrzymamy dzięki temu zrzut z pamięci podręcznej Google przedstawiający ostatnią zapisaną wersję wybranej podstrony, którą robot otrzymał od serwera. Wiemy dzięki temu, kiedy robot odwiedził ją ostatni raz.
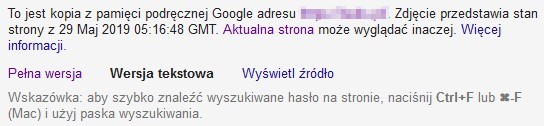
Nie jest to jednak wyrenderowana przez usługę WRS treść. Jest tutaj widoczny obraz tego, w jaki sposób przeglądarka, z której korzystamy interpretuje kod, jaki zebrał Googlebot odwiedzając daną witrynę. Przeglądarka – nie Google.
Dlatego nie można przywiązywać dużej wagi do tego, co tutaj otrzymujemy i w ten sposób podejmować decyzji o poprawności naszego kodu JS. Obraz witryny, jaki tutaj zobaczymy, to nie jest to, co w rzeczywistości jest indeksowane i oceniane przez algorytmy wyszukiwarki. Sam John Mueller wielokrotnie potwierdzał, że jest to jedynie podstawowy kod HTML, jaki Googlebot otrzymuje od serwera (bez wglądu w to jak Google go wyrenderował).
Jeśli natomiast chcemy zbadać, czy Google indeksuje poprawnie dane treści implementowane z pomocą JS na stronie, np. opisy kategorii, znacznie lepiej użyć do tego komendy site w kontekście danej podstrony, oraz wpisania z niej fragmentu tekstu w cudzysłów.
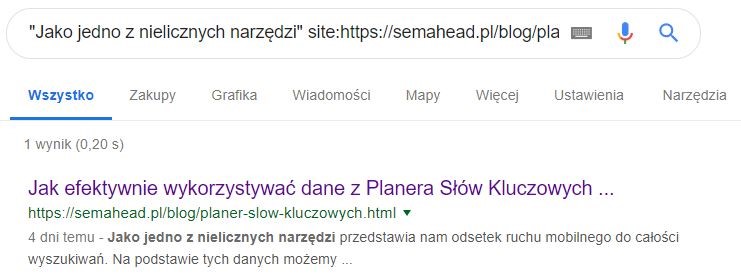
Jak widzimy powyżej, pogrubiony tekst został poprawnie zaindeksowany.
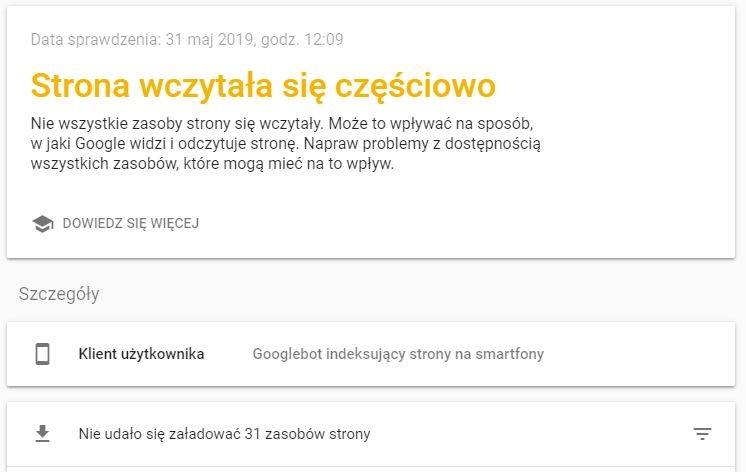
Istotne jest posiadanie dostępu do konta Google Search Console danej witryny. Za jego pomocą możemy zbadać dowolny adres URL, który do niej należy. Aby to zrobić wystarczy wpisać go w okienko znajdujące się w górnej części narzędzia i wcisnąć enter:

Po zakończonej pracy program wskaże nam podstawowe informacje na temat danej podstrony. Dowiemy się między innymi czy jest ona zindeksowana w wyszukiwarce, czy jest dostosowana do urządzeń mobilnych i tym podobne. Nam zależy jednak na sprawdzeniu jak Google radzi sobie z renderowaniem aktualnej wersji podstrony. Żeby to sprawdzić, klikamy więc w szary przycisk „Sprawdź URL wersji aktywnej”. Po nieco dłuższym czasie oczekiwania, możemy wyświetlić przetestowaną stronę. Dzięki zakładce „Zrzut ekranu” dowiemy się jak Google zobaczył naszą stronę. Należy mieć jednak świadomość, że nie otrzymamy tutaj pełnej długości strony, a najczęściej jedynie jej część.
Zakładka „Więcej informacji” wskaże nam wszystkie zasoby jakie wykrył Google, te, z którymi może sobie nie radzić (np. z powodu blokady dostępu przez plik robots.txt) oraz komunikaty z konsoli JavaScript.
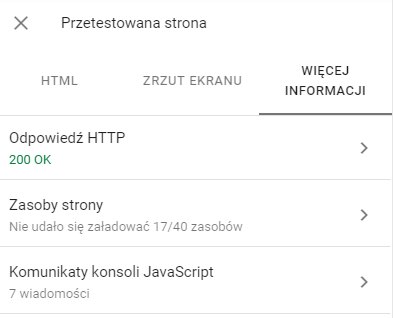
Oczywiście informacje podawane tutaj nie muszą być w 100% zgodne z rzeczywistością, jednak zalecam, aby dokładniej przyglądać się potencjalnych problemom z witryną.
Aby wyszukać niektóre błędy renderowania kodu naszej strony związane z niedopasowaniem do urządzeń mobilnych, możemy użyć specjalnie do tego przeznaczonego narzędzia Google dostępnego pod adresem: https://search.google.com/test/mobile-friendly. Pozwoli ono nam zajrzeć w wyrenderowany przez Google DOM oraz sprawdzić błędy konsoli, a także zasoby, które są blokowane przez robots.txt.
W tym miejscu chciałbym pokrótce omówić wybrane funkcje programu Screaming Frog, pozwalające na badanie Java Script w serwisach. Kiedy już otrzymamy raport dostępny po przecrawlowaniu witryny przez narzędzie (przy zachowaniu domyślnych ustawień), możemy dowiedzieć się czegoś więcej na temat odnalezionych przez program plików JS. Listę otrzymamy używając odpowiedniego filtrowania wyników:
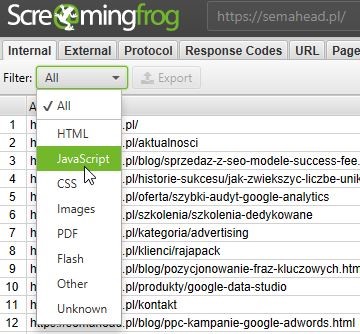
Otrzymamy w ten sposób bazę plików, które możemy sprawdzić pod kątem dostępności dla robotów, zwracanych przez nie kodów odpowiedzi, czy czasu odpowiedzi. Możemy także sprawdzić, gdzie w witrynie znajdują się odwołania do takich zasobów. W kontekście szybkości ładowania strony należy jednak pamiętać o ładowaniu asynchronicznym plików JS, które mogło zostać użyte w serwisie. Jeśli natomiast chcemy otrzymać widok tego, jak Google może renderować naszą witrynę, wówczas musimy odpowiednio skonfigurować Screaming Froga.
Na początku przechodzimy do opcji Spider:
Kolejnym krokiem jest przejście do zakładki „Rendering” i kliknięcie opcji „JavaScript”:
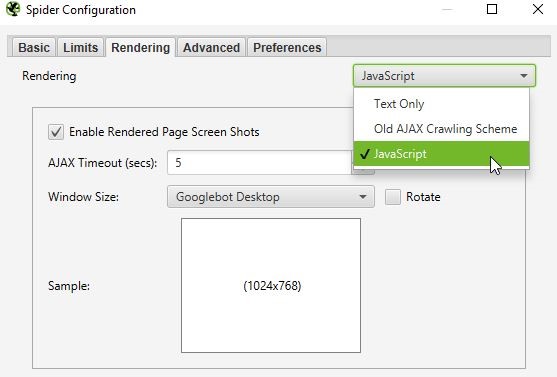
Co istotne, domyślnie crawler ma ustawione 5 sekund na wyrenderowanie danej podstrony zanim przejdzie do następnej (AJAX Timeout). Możemy to zmienić, jednak nie zalecam tego robić, z uwagi na to, że Google również ma ograniczony czas podczas wizyty w serwisie. Najczęściej może to być właśnie około 5 sekund.
W przypadku, kiedy skończy się czas, przełoży się to na brak widoku całej treści lub layoutu przez Google. Chodzi tutaj m.in. o crawl budget oraz render budget. Starajmy się więc, aby wyrenderowanie strony nie wymagało zbyt długiego czasu oczekiwania. Oprócz straconego potencjału crawl budgetu, możemy zniechęcić do witryny użytkowników, którzy opuszczą stronę, jeśli nie będzie ładowała się ona zbyt szybko.
Jak widzimy na poprzedniej grafice, w okienku konfiguracji robota pod kątem wykorzystania przez niego JavaScript mamy do wyboru różne typy rozdzielczości, jakie Screaming Frog będzie brał pod uwagę podczas crawlowania. Jedne z najbardziej przydatnych zostały nazwane „Googlebot Mobile: Smartphone” oraz „Googlebot desktop”. Skupmy się teraz na tej drugiej.
Oprócz tego warto zaznaczyć ptaszki obok dwóch opcji crawlu: „Store HTML” oraz „Store Rendered HTML”. Są one dostępne w zakładce „Advanced”. Dzięki nim otrzymamy do wglądu kod źródłowy oraz wyrenderowany DOM. Dodatkowo możemy wybrać odpowiedni rodzaj user-agent, jakiego ma używać Screaming Frog (np. Googlebot).
Po skończonej analizie otrzymujemy w raporcie między innymi:
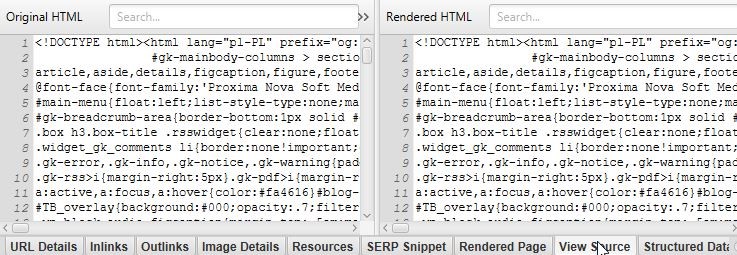
Jak widać, otrzymujemy tutaj więcej informacji na temat witryny niż podczas standardowego crawlu. Trzeba jednak pamiętać, że renderowanie JavaScript jest czasochłonne i zebranie danych o całym serwisie będzie znacznie dłużej trwać.
Chciałbym zaznaczyć, że nie należy ufać wszystkiemu, co tutaj zaobserwujemy. Jest to spowodowane brakiem możliwości całowitego wcielenia się robota Screaming Froga w rolę Google oraz w sposób jego chodzenia po witrynie.
Dodam jeszcze, że oprócz Screming Froga renderowanie JavaScript na stronie oferują inne crawlery, m.in. Sitebulb. Natomiast więcej na temat konfiguracji oraz zaawansowanego użycia Screaming Froga znajduje się w innym artykule: Jak crawlować duże serwisy za pomocą Screaming Froga?

Wyłączenie obsługi kodu JavaScript w przeglądarce jest możliwe na kilka sposobów. Osobiście korzystam z odpowiedniej funkcji dostępnej we wtyczce „Web Developer” (można ją instalować m.in. w Chrome). Po wybraniu tej opcji, należy odświeżyć stronę, na której się znajdujemy.
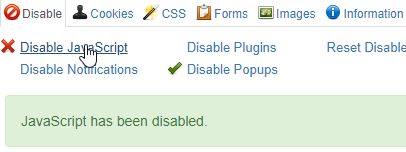
Ta metoda co prawda nie przybliży nas do sprawdzenia tego, jak Google widzi daną witrynę, jednak w bardzo prosty sposób dowiemy się, w jaki sposób strona jest widoczna z wyłączoną obsługą kodu JavaScript. Jest to podstawa, jeśli modyfikujemy serwis za pomocą skryptów i chcemy dowiedzieć się, czy nie wpływa to negatywnie na widoczność głównych treści.
Pamiętajmy, że najlepsza droga do tego, aby Google indeksował sprawnie nasz serwis, to dobra widoczność linków, tekstów oraz grafik bez potrzeby renderowania kodu JS. Jeśli korzystamy więc z zaawansowanych sposobów serwowania treści użytkownikom, korzystajmy z odpowiednich mechanizmów fallback.
Innymi słowy: postarajmy się, aby elementy witryny, takie jak grafiki były widoczne tak samo w sytuacji, kiedy przeglądarka obsługuje JavaScript oraz kiedy takiego kodu nie obsługuje. Przykład kiedy możemy się z tym spotkać to tzw. „lazy loading”. Mechanizm ten stosowany jest w celu przyspieszenia ładowania się serwisu poprzez doczytywanie grafik dopiero wtedy, kiedy znajdą się w polu widzenia użytkownika. Znajdują się one poniżej aktualnego widoku w przeglądarce i ładowane są niejako „w tle”.
Fallbackiem w tym przypadku będzie zastosowanie rozwiązania, które pozwoli na pojawienie się tych samych grafik co wcześniej na danej podstronie przy wyłączonej obsłudze kodu JavaScript. Nieco upraszczając, jedną z możliwości jest tutaj użycie tagu HTML <noscript> i umieszczenie w nim odpowiedniego adresu obrazka. Powinien on ładować się w drzewie DOM jedynie w przypadku braku obsługi JavaScript.
W kontekście crawlowania jest to o tyle istotne, że googlebot może od razu z łatwością dotrzeć do danych obrazków i zaindeksować je bez potrzeby renderowania JS. Zrobi więc to zawsze szybciej i sprawniej, zwłaszcza jeśli treści na stronie zmieniają się dość często.
Bardzo pomocnym narzędziem do badania skryptów są narzędzia deweloperskie Google. Dostępne są po kliknięciu przycisku „Zbadaj” w dowolnym miejscu na stronie internetowej. Przykładowo w sekcji „Network” dowiemy się m.in. jakie pliki są wczytywane podczas ładowania strony, jak szybko oraz w jakiej kolejności.
Kiedy przejdziemy do tej zakładki należy odświeżyć stronę za pomocą „Ctrl +R”. Wówczas otrzymamy odpowiednie dane do analizy. Na górnym pasku (1) możemy filtrować listę pobieranych zasobów (2) po ich typie. Widzimy tutaj również rozmiar (4) poszczególnych plików, czas potrzebny do ich pobrania (5) oraz te dwa elementy razem, przedstawione w formie graficznej (6).
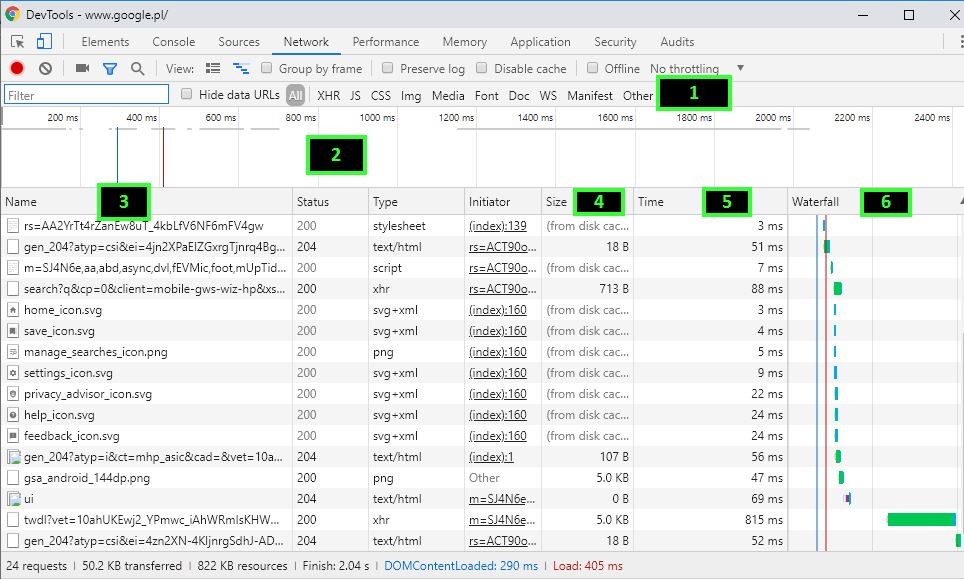
Z danych dowiemy się m.in. jakie zasoby zajmują najwięcej czasu na pobranie oraz czy kolejność ładowania poszczególnych zasobów jest poprawna. Zbędne skrypty mogą blokować istotne treści ponieważ ładują się przed nimi, zamiast być renderowane asynchronicznie.
Szczegółowe wyjaśnienie jak efektywnie wykorzystywać potencjał tych narzędzi znajduje się między innymi tutaj.
Jeśli chcemy zacząć śledzić ruchy i zachowanie googlebota w trakcie jego przebywania w obrębie naszej witryny – warto korzystać z dobrodziejstw analizy logów serwera. Logi serwera są bardzo przydatne w celu wyszukiwania błędów oraz prac nad optymalizacją witryny.
Kiedy już pozyskamy logi serwera dotyczące ruchu robotów w witrynie (ruch użytkowników nie jest nam tutaj potrzebny) od webmastera, obsługi hostingu lub na własną rękę, możemy zacząć je analizować. Wystarczy jeśli użyjemy do tego zwykłego Excela, jednak do sprawnego wyciągania interesujących nas danych potrzebna może okazać się zaawansowana wiedza z zakresu znajomości tego programu oraz duża ilość pamięci RAM. Przykładowym przydatnym narzędziem, które usprawni naszą pracę jest Screaming Frog File Analyser.
Zyskamy dzięki niemu łatwy dostęp do wielu danych, np. na temat tego co odwiedzają roboty, jak często, ile czasu spędzają danego dnia w naszej witrynie oraz jakie kody odpowiedzi otrzymują w trakcie wysyłania żądań.
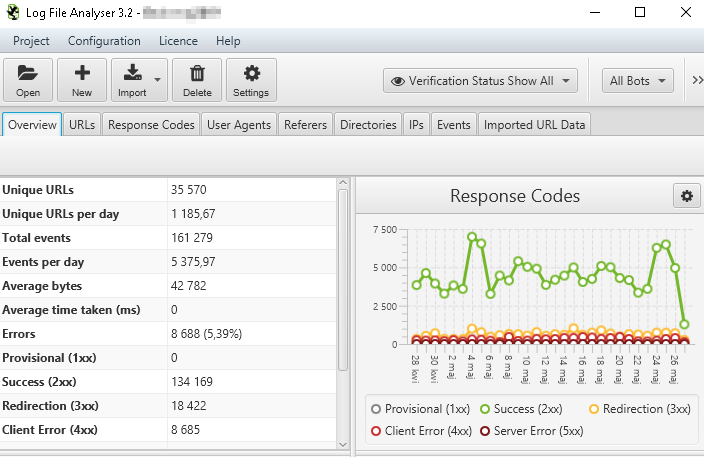
Dzięki posiadaniu takich danych możemy dowiedzieć się do jakich zasobów roboty docierają, z jakimi sobie nie radzą i których używają zbyt często. Mamy dostęp do wszystkich podstron, jakie zobaczył googlebot. Sprawdzimy więc, czy implementacja skryptów na stronie najprawdopodobniej nie przeszkadza w dostaniu się do danej części serwisu, np. przez obecne na stronie linki generowane za pomocą JS. Dowiemy się tego na przykład poprzez wyszukanie danej podstrony na liście oraz ewentualnie porównaniu ilości odwiedzin jej przez robota w porównaniu do pozostałych stron.
Sprawdzimy także, czy dane strony nie obciążają zbyt bardzo jego „mocy przerobowych”, przez co niektóre strony mogą być pomijane. Zrobimy to sortując w programie listę podstron oraz zasobów według częstotliwości ich odwiedzin. Przykładowo: na poniższym screenie widzimy, że jeden rekord generuje aż 9 339 żądań, co w porównaniu do pozostałych elementów na liście stanowi sporą wartość.
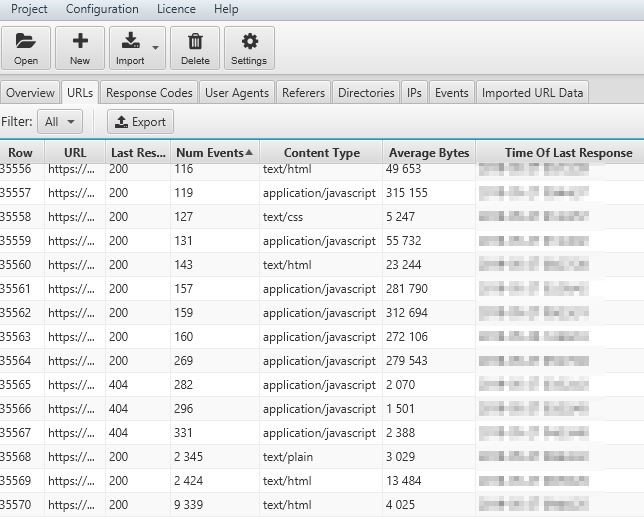
Ilość żądań dla plików JavaScript, CSS oraz strony głównej nie odbiega od normy, dlatego możemy stwierdzić, że omawiany tutaj zasób stanowi problem podczas crawlowania. Może być to związane z np. z zastosowanymi dla niego technologiami. Po sprawdzeniu podstrony okazuje się, że jest ona wykorzystywana w procesie zakupowym. Możemy więc zablokować robotom dostęp do takiego pliku, co powinno przełożyć się na optymalizację crawl budgetu. Dodam, że Screaming Frog z włączonym renderowaniem JavaScript nie odnalazł tej podstrony.
Logi serwera pozwalają na zbadanie wielu zachowań robotów i reagowanie do pewnego stopnia na to jak wykorzystują czas w serwisie, jednak nie jest oczywiście możliwe dokładne zrozumienie ich przez nas.
Renderowanie kodu JavaScript może odbywać się na kilka sposobów. Jednym z nich jest renderowanie po stronie klienta. Możemy spotkać je dość często w Internecie. Klientem może być np. przeglądarka lub robot Google. Jak już wspominałem wcześniej, interpretacja skryptów i prezentowanie jej w odpowiednim środowisku wymaga zasobów mocy obliczeniowej. Często mogą być one bardzo duże, głównie z uwagi na ilość zastosowanych elementów JS, stopień optymalizacji kodu lub błędy, które może on generować. Co więc zrobić, jeśli chcemy pomóc robotowi w osiągnięciu lepszej dostępności treści strony?
Obecnie najprawdopodobniej jedynym sposobem na to, aby Google nie miał problemów z interpretacją kodu JavaScript, jest renderowanie tego typu skryptów po stronie serwera i przesyłanie tzw. HTML snapshots. Innymi słowy: możliwe jest wykorzystanie zasobów serwera do tego, aby googlebot błyskawicznie otrzymywał gotową, wyrenderowaną treść. Co istotne, oprócz szybkiego otrzymania zawartości serwisu przez roboty, najprawdopodobniej istotnie poprawi się wynik czasu ładowania strony.
Renderowanie po stronie serwera jest znacznie chętniej stosowane przez aplikacje internetowe, ponieważ ich budowa może w znacznym stopniu opierać się na kodzie JavaScript oraz jego frameworkach. Warto dodać, że jeśli kod naszej stronie jest bardzo skomplikowany oraz zależy nam na poprawnym zrozumieniu wszystkich treści przez roboty, to prerenderowanie może okazać się dobrym pomysłem. Warto jednak pamiętać o jego wadach – głownie jest to dodatkowe obciążenie serwera i zwiększony koszt z powodu zwiększenia ilości serwowanych zasobów.
Dobrym narzędziem, które pomaga w renderowaniu strony po stronie serwera jest https://prerender.io/.
Zainteresowanych odsyłam po więcej do wiedzy przedstawionej przez Google: https://developers.google.com/web/tools/puppeteer/articles/ssr
Optymalne wydaje się używanie prerenderowania jedynie dla robotów wyszukiwarki. Należy jednak pamiętać, że poprawny efekt uzyskamy, kiedy odpowiednio skonfigurujemy serwer tak, aby po wykryciu odpowiedniego user-agenta serwował robotowi wyrenderowaną treść, natomiast użytkownikowi zwykłą. Co istotne, te dwie wersje nie powinny różnić się między sobą jeśli chodzi o główne treści oraz linki wewnętrzne. Wyrenderowane drzewo DOM musi odpowiadać temu, co przesyłamy robotom. W innym przypadku możemy narazić się na karę od Google.
Tym, co zaleca sam Google, jest wykorzystywanie izomorficznego kodu JavaScript. Pozwala on na prerenderowanie treści strony zarówno dla użytkownika jak i robota w ten sam sposób. Co istotne, nie wszystkie frameworki, których używamy w serwisie obsługują renderowanie po stronie serwera.
Dostępne rodzaje renderowania stron i aplikacji internetowych to:
1. Client side rendering – renderowanie po stronie klienta (robota oraz przeglądarki internetowej).
2. Server side rendering – renderowanie odbywa się po stronie serwera, każdy klient (przeglądarka oraz robot) otrzymuje gotowy, statyczny HTML.
3. Hybrid rendering – klient-przeglądarka oraz crawler otrzymują wyrenderowany przez kod HTML, a dopiero później serwer przesyła kod JavaScript.
4. Dynamic rendering (sposób preferowany przez Google) – po wykryciu informacji o user-agent przez stronę klient w postaci crawlera otrzymuje statyczny HTML po wcześniejszym wyrenderowaniu kodu JavaScript przez serwer, natomiast klient-przeglądarka otrzymuje standardową wersję strony.
JavaScript to wciąż trudny temat dla robotów Google. Chociaż firma deklaruje, że radzi sobie sprawnie z renderowaniem go oraz indeksacją w wyszukiwarce, zalecam uzasadnione używanie tego typu kodu. Opierajmy się przede wszystkim na semantyce kodu HTML oraz optymalizacji SEO naszych witryn. Animacje, używanie JS w celu dodania zbędnych „fajerwerków” może być niekiedy zabójcze dla prędkości ładowania oraz sprawnej indeksacji serwisu.


Chcesz zacząć współpracę z nami? Wypełnij formularz!
Wypełnienie zajmie Ci kilka chwil a nam pozwoli
lepiej przygotować się do rozmowy z Tobą.
