

Dziękujemy za wypełnienie formularza kontaktowego!
Twoja wiadomość już do nas leci - napiszemy bądź zadzwonimy do Ciebie tak szybko, jak to możliwe.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:


I fru... Twoja wiadomość już leci na nasze skrzynki!
Zajrzyj na swoją pocztę, aby poznać szczegóły oferty ;)
Tymczasem, sprawdź nowości na naszym blogu semahead.agency/blog/
Zespół Semahead by WeNet
Dziękujemy za zapis do Newslettera!
Na Twoją skrzynkę wysłaliśmy wiadomość potwierdzającą subskrypcję.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:
'
Dziękujemy za wypełnienie formularza zgłoszeniowego!
Twój formularz już do nas leci - za chwilę otrzymasz informację zwrotną na podany w zgłoszeniu email.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, możesz zajrzeć na nasze social media:

Używasz Screaming Froga i zastanawiasz się, jak usprawnić jego działanie? Jak wykorzystać w pełni jego możliwości i pomóc sobie w analizie dużej witryny? Poznaj przydatne sposoby na optymalny crawl z użyciem właśnie tego narzędzia.
W pracy specjalisty SEO zdarza się, że w trakcie wykonywania audytu SEO lub po jego zakończeniu potrzebne są konkretne dane na temat zawartości serwisu, który badamy. Wiele osób używa do tego znanego w branży narzędzia, jakim jest Screaming Frog. Pozwala on na badanie witryn pod kątem tytułów stron, meta description, nagłówków, linków wychodzących, kodów odpowiedzi oraz wielu innych.
W przypadku małych serwisów wykonanie crawlu za pomocą tego programu jest stosunkowo szybkie. Co jednak w przypadku, kiedy mamy do czynienia z dużymi serwisami z setkami tysięcy podstron? Warto wówczas znać zaawansowane funkcje Screaming Froga. W tym artykule wskażę przydatne metody na crawl dużych witryn – właśnie dzięki ich wykorzystaniu.
W zależności od poziomu zaawansowania wykorzystujemy różne funkcjonalności popularnych crawlerów. Jeśli znamy już po części dany serwis, musimy rozpoznać typ problemu, jaki chcemy zbadać. Wtedy możemy postawić sobie cel wykonania kolejnego crawlu witryny.
Przykłady zastosowań Screaming Froga w codziennej pracy ze stroną www to:
Kiedy już wiemy, co mamy do wykonania, możemy śmiało przejść do ustawień Screaming Froga. W programie mamy możliwość zapisania własnych konfiguracji w osobnym pliku, a także wczytania go i użycia zawartych w nim ustawień. Zrobimy to za pomocą przycisku „Save As” (zakładka „File” -> „Configuration”).
Możemy również zapisać naszą konfigurację jako domyślną („Save Current Configuration As Default”) – program wraz z każdym kolejnym uruchomieniem wróci do tych ustawień. Jeszcze inna opcja to powrócenie do domyślnych ustawień przygotowanych przez Screaming Froga od początku („Clear Default Configuration”).
Nas natomiast najbardziej interesuje tutaj dostępna w menu głównym zakładka „Configuration” oraz jej poszczególne funkcje. Jej użycie zależne jest od prac nad danym serwisem.
Dobrze, jeśli pierwszy crawl wykonany jest w sposób „deafultowy”. Jeszcze nie wiemy, z czym mamy do czynienia i nie chcemy w żaden sposób ograniczać robota w jego pracy. W ten sposób możemy wykryć rodzaj błędów, z jakimi mamy do czynienia.
W późniejszym etapie, kiedy chcemy poznać źródło danego problemu oraz skupić się na nim głębiej – zalecam stosowanie odpowiednich wykluczeń oraz ustawień.
Zacznijmy od zakładki „Spider”. Funkcjonalność ta dotyczy głównych ustawień naszego crawlera – w głównej mierze tego, co może on robić na danej stronie i co crawlować, a czego nie. Poniżej kilka przydatnych elementów.
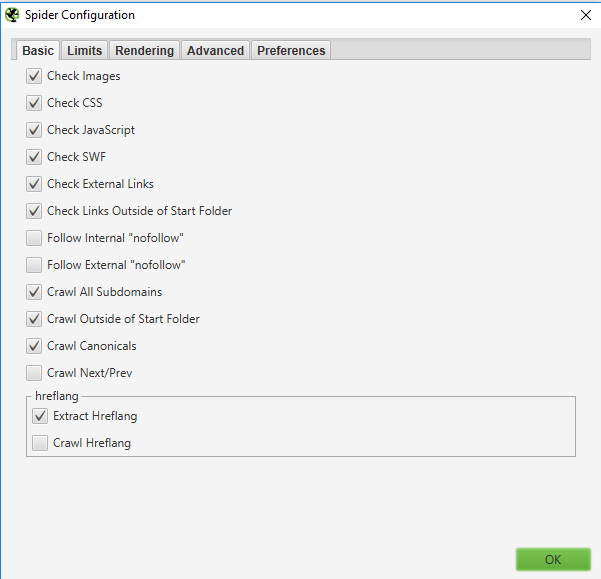
Jak widać powyżej, mamy tutaj wiele opcji do wyboru. Możemy wykluczyć sprawdzanie obrazków, plików CSS, JS czy SWF. Jeśli szukamy np. wewnętrznych przekierowań 301 między podstronami, nie potrzebujemy pozostałych danych.
Podobna sytuacja występuje z linkami wychodzącymi. Nie ma tutaj potrzeby otrzymania raportu z zewnętrznymi bibliotekami, z których korzysta strona czy linków do zewnętrznych domen.
Tutaj wykluczymy wykonywanie crawlu linków nienależących do danego folderu. Po odznaczeniu tej opcji skupimy uwagę wyłącznie na np. danej kategorii sklepu lub jednej zakładce w menu.
Oprócz oczywistej oszczędności czasu możemy wykorzystać tę opcję jako dodatek do bardziej zaawansowanych funkcji, takich jak wyszukiwanie i pozyskiwanie określonych danych znajdujących się w danej sekcji, np. tytułów artykułów na odsłonie bloga. W ten sposób dowiemy się np. o występującej duplikacji nagłówków H1 w obrębie danej kategorii produktów.
Pamiętajmy jednak, że po zaznaczeniu tej opcji robot nie będzie podążał w głąb witryny za linkami z danego folderu, a jedynie sprawdzi linki bezpośrednie, które znajdują się w kodzie startowej podstrony.
W tym miejscu ustawimy podążanie robota za linkami z atrybutem rel=”nofollow” istniejącymi w obrębie serwisu. W ten sposób znajdziemy podstrony, do których robot wcześniej mógł nie dotrzeć.
Dzięki tej opcji wykluczymy crawlowanie adresów kanonicznych. Jeśli w obrębie witryny znajduje się wiele linków kanonicznych, możemy wykluczyć ich crawlowanie. Pamiętajmy jednak, że takie linki nadal mogą pojawić się w raporcie z powodu znalezienia się w pozostałym kodzie HTML (jako zwykły link).
W ten sposób zmniejszymy czas crawlu. Należy jednak pamiętać, że podstrona wskazana jako kanoniczna może różnić się w dużym stopniu od tej „powielonej”.
Możemy również crawlować linki zawarte w atrybutach rel=”next” oraz rel=”prev”. Użyjmy tej opcji, jeśli chcemy sprawdzić, czy linki wskazane, jako „next” lub „prev” różnią się od tych kryjących się za przyciskami przejścia do następnej strony paginacji.
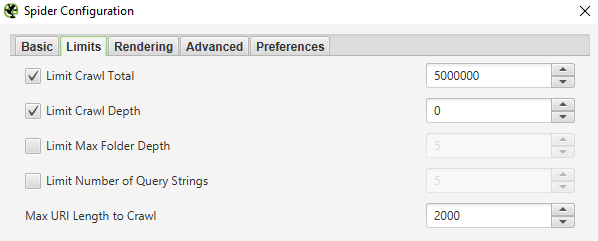
W tej zakładce możemy ustawić limity, jakich ma przestrzegać nasz crawler. Są to:
Mówiąc najkrócej, jest to limit „oddalania się” od strony startowej. Opcja przydaje się szczególnie wtedy, gdy mechanizm filtrowania na stronie nie działa poprawnie. Dzięki niej możemy zapobiec „zapętleniu się” naszego robota.
Jeśli chcemy zbadać podstawową strukturę głównego menu na stronie głównej lub zbadać do jak wielu podstron możemy dotrzeć według zasady 3 kliknięć ze strony głównej, użyjmy tej opcji.
Jeżeli zaś naszym celem jest poznanie sumy linków wewnętrznych wychodzących z danej podstrony, użyjmy limitu „1”. Przy większych serwisach możemy w ten sposób badać różne typy stron oraz znajdujące się w nich linki .
Przez zastosowanie wartości limitu dla tej opcji możemy zapobiec głębokiemu crawlowaniu przez naszego robota. Należy jednak pamiętać, że nie zawsze liczba folderów danego adresu URL idzie w parze z liczbą podstron, po których musi przejść dany robot lub użytkownik, aby się do niego dostać. Przykładowo na stronie głównej może istnieć link do adresu: domena.pl/kat/kat2/kat3/kat4/kat5.
Innymi słowy: przez jednoczesne zastosowanie tej oraz poprzedniej opcji (Limit Crawl Depth) wykluczymy linki pochodzące np. ze strony głównej, które mają więcej niż np. 5 folderów.
Jeśli znamy już strukturę danej strony i wiemy, że jej produkty i/lub usługi znajdują się w obrębie adresów URL w czwartym katalogu zagnieżdżenia, możemy użyć limitu z wartością „3”. W ten sposób pominiemy crawl produktów i skupimy się na kategoriach oraz innych podstronach z maksymalną ilością 3 katalogów w adresie URL.
Limit Max folder Depth przyda się również do wylistowania wszystkich kategorii pierwszego rzędu i przypisania im fraz kluczowych.
Przez zastosowanie tego limitu wykluczymy daną liczbę parametrów występujących w adresie URL, jakie powinien crawlować nasz robot. Przykładowo: przy zastosowaniu limitu „1” robot zwróci adresy tylko z jednym parametrem (domena.pl/produkt?=x). Jeśli użyjemy limitu „0” nie otrzymamy żadnych adresów URL z parametrami.
Chodzi tutaj o nadanie limitu długości dla znaków występujących w adresie URL. Jest to opcja używana stosunkowo rzadko. Co istotne, do odfiltrowania niepotrzebnych w danym raporcie podstron, polecam użycie poprzednich opcji.

Zakładka ta dotyczy sposobu, w jaki robot będzie renderował dany serwis. Mamy 3 możliwości wyboru.
Dodatkowo, po wybraniu tej opcji wyświetli nam więcej elementów do wyboru.
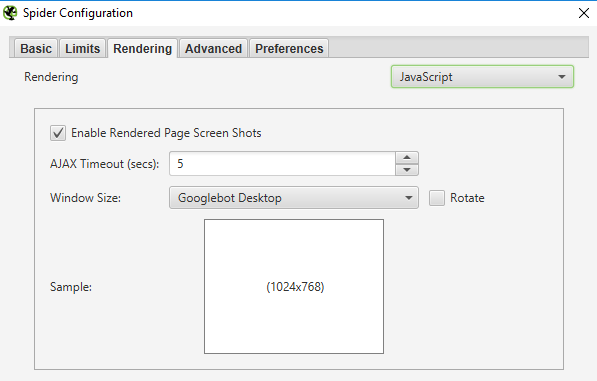
Chodzi tutaj o możliwość włączenia tworzenia screeshotów dotyczących tego, co „widzi” SF oraz umieszczania ich w folderze na dysku, na którym jest on zainstalowany. W ten sposób dowiemy się, jak wygląda strona po zrenderowaniu jej przez robota po określonej długości czasu oczekiwania (opcja AJAX Timeout (secs)).
Obrazy, które wyrenderował Screming Frog są dostępne w zakładce „Renedered Page”.

Otrzymamy tutaj informację o wszystkich zasobach, których używa dana podstrona. Możemy wśród nich wyselekcjonować tylko te, które powodują błędy w prawidłowym renderowaniu się strony.
Screenshoty tego, jak została zrenderowana strona możemy również pobrać do dowolnego folderu poprzez użycie opcji „Screenshots” (zakładka „Bulk Export” -> „Screenshots”).
Pamiętajmy o tym, że używając tej opcji, zwiększamy znacznie czas trwania crawlowania przez robota. Aby zrobić to sprawnie, rekomenduję użycie odpowiednich limitów crawlowania.
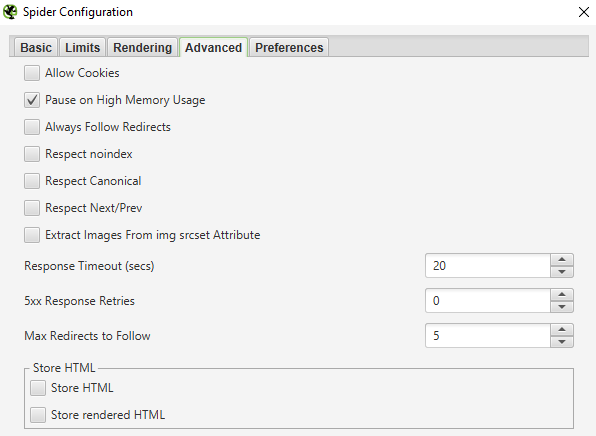
W zakładce „Advanced” mamy możliwość ustawienia następujących opcji:
Po zaznaczeniu tej opcji Screaming Frog będzie zawsze brał pod uwagę dyrektywy przekierowań 3XX, ignorując jednocześnie „głębokość crawlu”. Funkcja ta jest przydatna, jeśli migrujemy serwis na inne adresy URL lub zmieniamy w dużej części jego strukturę.
Możemy znaleźć pętle przekierowań, wielokrotne przekierowania w sposób bardziej dokładny niż na ustawieniach domyślnych, gdzie SF może nie wskazać wszystkich „głębokich przekierowań”. Aby zobaczyć, nad jakimi przekierowaniami wewnątrz serwisu musimy popracować, najlepiej pobrać na dysk raport „Redirect Chains”.
W tym raporcie otrzymamy adresy URL z obrębu serwisu, które są przekierowywane 2 lub więcej razy. Należy pamiętać, że nie znajdziemy tutaj pojedynczych przekierowań.
Jeśli mamy do czynienia z bardzo powolnym serwisem, natomiast chcemy uzyskać o nim jak najwięcej rzetelnych informacji możemy zwiększyć czas oczekiwania przez SF na odpowiedź HTTP powyżej domyślnych 20 sekund.
Jeśli serwer, na którym stoi strona jest obciążony lub niewydolny i otrzymujemy wiele podstron z kodem 5XX możemy użyć tej opcji i zwiększyć liczbę prób dostania się przez SF do danej części serwisu po początkowym otrzymaniu kodu 5XX. Zwiększa to czas trwania crawlu, jednak dzięki temu ograniczymy ilość wystąpienia błędów serwera przez chwilową jego niewydolność, a otrzymać w raporcie głównie te podstrony, które generują stałe błędy 5XX.
Możemy tutaj określić, jak długą ścieżkę przekierowań ma uwzględnić w raporcie Screaming Frog. Domyślnie robot podąża za maksymalnie pięcioma kolejnymi przekierowaniami.
W tej zakładce znajdziemy też inne przydatne funkcje, jak choćby wyciąganie obrazków z atrybutem srcset – zdarza się, że jest on stosowany w responsywnych serwisach. Dzięki niemu można umieścić ten sam obrazek, ale w różnych rozdzielczościach.
W zakładce „Exclude” wykluczymy dane podstrony z parametrami, których nie chcemy otrzymać w końcowym raporcie. Mogą to być na przykład podstrony powstałe w wyniku użycia filtrowania. Dodatkowo skraca to czas crawlowania.
Poniżej znajduje się przykład wykluczenia wielu parametrów.
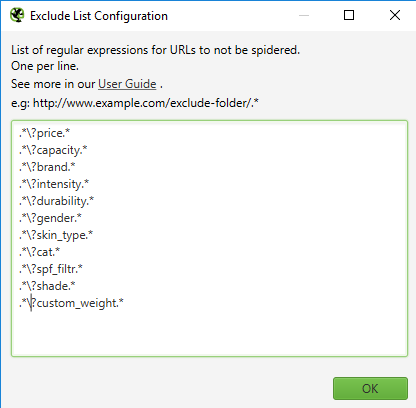
W ten sposób możemy również wykluczyć z crawlu konkretne foldery lub adresy URL zawierające dane słowa.
W zakładce „Speed” mamy możliwość przyspieszenia lub zwolnienia działania Screaming Froga.
Istnieją dwie opcje:
1. Zmiana liczby wątków
Więcej wątków oznacza więcej zapytań do serwera, co może spowodować jego zbytnie obciążenie. Zwiększając ilość wątków, wpływamy na czas odpowiedzi strony i otrzymujemy w konsekwencji przekłamane dane odnośnie szybkości jej działania.
Zatem aby manewrować tą opcją, najpierw warto znać możliwości serwera. Dobrze jest poinformować administratora o tym, że coś takiego będzie miało miejsce i poprosić, by dodał nasz adres IP do zaufanych.
2. Zmiana limitu crawlowanych adresów URL na sekundę
Dzięki tej opcji ograniczymy liczbę adresów URL crawlowanych na sekundę, co może przełożyć się na większą dokładność – przydatne przy analizie małych serwisów lub tylko części witryny.
Jeśli pamięć RAM, jaką dysponujemy na komputerze, jest mała, możemy zmienić typ zapisywania danych z pamięci RAM na dysk twardy. Dzięki czemu SF może być bardziej efektywny. Aby wybrać taką opcję, należy skorzystać z zakładki „Storage” (zakładka „Configuration” -> „System” -> „Storage”), a następnie wybrać opcję Database Storage:
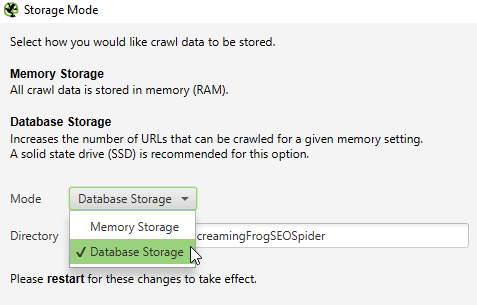
Reasumując, przy wykonywaniu kolejnych crawli naszego serwisu musimy wiedzieć, do jakich danych chcemy tak naprawdę dotrzeć. Znając odpowiednie opcje SF, możemy obniżyć znacząco czas crawlu i własny czas, który musielibyśmy poświęcić na szukanie odpowiednich danych z domyślnych raportów.
Jeśli chcemy, żeby crawlowanie dużego serwisu było maksymalnie efektywne (optymalne) musimy zastanowić się m.in.:


Chcesz zacząć współpracę z nami? Wypełnij formularz!
Wypełnienie zajmie Ci kilka chwil a nam pozwoli
lepiej przygotować się do rozmowy z Tobą.
