

Dziękujemy za wypełnienie formularza kontaktowego!
Twoja wiadomość już do nas leci - napiszemy bądź zadzwonimy do Ciebie tak szybko, jak to możliwe.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:


I fru... Twoja wiadomość już leci na nasze skrzynki!
Zajrzyj na swoją pocztę, aby poznać szczegóły oferty ;)
Tymczasem, sprawdź nowości na naszym blogu semahead.agency/blog/
Zespół Semahead by WeNet
Dziękujemy za zapis do Newslettera!
Na Twoją skrzynkę wysłaliśmy wiadomość potwierdzającą subskrypcję.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, zajrzyj na nasze social media:
'
Dziękujemy za wypełnienie formularza zgłoszeniowego!
Twój formularz już do nas leci - za chwilę otrzymasz informację zwrotną na podany w zgłoszeniu email.
Pozdrawiamy
SEMAHEAD by WeNet
Tymczasem, możesz zajrzeć na nasze social media:

Jako że gościnność jest jedną z kluczowych cech specjalistów SEO, to duża część pracy SEO-wca polega na przygotowaniu witryny do jak najczęstszych odwiedzin botów indeksujących. Podczas każdego przyjęcia jest tak, że wszyscy bawią się i biesiadują w jednym pomieszczeniu, inne pokoje zaś nie są dostępne dla odwiedzających – ma do nich dostęp tylko gospodarz. Podobnie jest z SEO-imprezami. Boty indeksujące w ciągu godziny przemierzają niezliczoną liczbę podstron, a wszystko to po to, by zaserwować użytkownikom najbardziej trafne informacje. Nie każda podstrona powinna być jednak skanowana i wskazane jest, by zablokować do nich dostęp – niektóre są zbędne, inne niepotrzebna, a jeszcze inne pełnią funkcje tylko techniczne.
Robots.txt to plik tekstowy, czyli zapisany w formacie .txt, który zawiera informacje dla robotów crawlujących (zwanych również user-agentami) o tym, które podstrony można odwiedzać, a których nie. Oznacza to, że w składni pliku mogą pojawić się zarówno formuły zezwalające na dostęp, jak i te blokujące odwiedziny. Co to oznacza w praktyce? Strony takie jak Google, Bing, Ahrefs i inne tego typu mają do dyspozycji tak zwane boty, które pozwalają na przemierzanie Internetu w poszukiwaniu treści. Następnie znalezione podstrony i pliki są skanowane, analizowane i indeksowane. Robots.txt z kolei dookreśla, czy dany robot może przeskanować i przeanalizować konkretną część witryny. Domyślnie crawlowane jest wszystko, co się da, zgodnie z zasadą – jeśli coś nie jest zakazane, to jest dozwolone.
Poprawny plik tekstowy robots.txt powinien znajdować się w folderze głównym domeny i dostępny pod adresem nazwadomeny.pl/robots.txt. Na przykładzie agencji Semahead: https://semahead.agency/robots.txt. Dla jednej domeny powinien występować tylko jeden plik robots.txt o takiej właśnie nazwie. Kluczowe jest umieszczenie pliku robots.txt we właściwym miejscu, by można go było zawsze odnaleźć pod właściwym adresem. Jest to ważne, ponieważ roboty Google rozpoczynają skanowanie domeny od odwiedzenia właśnie tego pliku i sprawdzają go nieomal rutynowo. Jeśli umieścimy go w podkatalogu np. https://example.com/pages/robots.txt), będzie już niedostępny dla robotów Google, gdyż będą go szukać w innym miejscu.
Ważnym elementem pracy SEO-wca jest zadbanie, by domena wysyłała właściwe sygnały. Poprzez słowo „właściwe” rozumiane jest to, byśmy komunikowali robotom maści wszelakiej dokładnie to, co chcemy. Dokładnie jak na randce z Tindera – jeśli nie sprecyzujemy naszych oczekiwań od początku, to możemy dostać coś, czego wcale nie chcieliśmy. Tinder daje nam opcje zaznaczenia, czy interesuje nas „coś na dłużej” bądź też „krótkoterminowa relacja” – plik robots.txt również daje nam taką możliwość, a dzieje się to przy pomocy dyrektyw. Dyrektywy to instrukcje indeksowania danej strony. Jeśli w danym pliku robots.txt nie ma żadnej dyrektywy, roboty będą skanować całą witrynę bez wahania. Po prostu będą przechodzić po każdej podstronie aż do momentu wyczerpania crawl budgetu.
By mieć pełną jasność: budżet indeksowania (crawl budget) to liczba podstron, które Google jest w stanie przeanalizować, przeskanować i zaindeksować w określonym czasie za określoną sumę pieniędzy. Jeśli Google skanuje podstrony, które są błędne, prezentują niską jakość bądź też nie zawierają żadnych istotnych informacji z punktu widzenia zarówno Google, jak i użytkownika – to marnowany jest w ten sposób crawl budget, a pieniądze wydawane są na podstrony bezwartościowe.

Mimo że plik robots.txt służy do zarządzania kontaktem z robotami, nie każdy robot będzie stosował się do zaleceń. Większość najpopularniejszych robotów, takich jak boty wyszukiwarek, będzie stosować się do dyrektyw. Jednak nie każdy i nie zawsze. Dyrektywy w pliku robots.txt są wyraźnym sygnałem dla robotów, ale należy pamiętać, że plik robots.txt jest zbiorem opcjonalnych dyrektyw dla wyszukiwarek, a nie nakazem. Słowo opcjonalne jest tutaj kluczowe – to tylko rekomendacje i wskazówki.
Co pocieszające, nawet jeśli pomylisz się i zapędzisz, to robot Google jest wyrozumiałym partnerem i zinterpretuje to bezpiecznie, czyli indeksując podstrony. Czy to oznacza, że nic się nie stanie, nawet jeśli zaszalejemy w pliku robots.txt? Otóż może się stać: jak powiedział dyrektor SEO z Shopify – „The robots.txt is the most sensitive file in the SEO universe. A single character can break a whole site” (https://www.contentkingapp.com/academy/robotstxt/). Dlatego też warto pamiętać, że choć Google jest wyrozumiały, nawet on może stracić cierpliwość dla ułańskiej fantazji SEO-wców, więc nie warto przesadzać z kreatywnością w tworzeniu dyrektyw.
Trzeba ze szczególną uwagą tworzyć plik robots.txt i nie wpisywać tam, co popadnie – to ważny plik, który może zaważyć na tym, co jest bądź nie jest indeksowane w Google. Sygnały, które wysyłamy przy pomocy dyrektyw, powinny być jednoznaczne.
Narzędzia dla developerów od Google jako przykład prawidłowo skonstruowanego pliku robots.txt podają:

Rozkładając go na czynniki pierwsze:
Jeśli mówimy o budowie pliku robots.txt, to powinien on być zakodowany UTF-8, a w jego składni powinny znajdować się wyłącznie znaki z kodu ASCII. Google może nieprawidłowo zrozumieć znaki spoza zakresu UTF-8, przez co reguły w pliku robots.txt mogą być rozumiane nieprawidłowo.
W pliku robots.txt jedna komenda zajmuje jeden wiersz. Plik powinien zawierać co najmniej jeden zestaw reguł. Każdy zestaw dyrektyw jest wyświetlany osobno, rozpoczyna się dookreślenia user-agenta i odznaczany pustym wierszem. Cytując za narzędziem dla developerów od Google, wiemy, że grupa ta powinna zawierać informacje:
Przykładem może być strona Semahead, która zawiera jeden zestaw rekomendacji dla wszystkich robotów zwanych również klientami – jest to jeden zestaw dyrektyw:
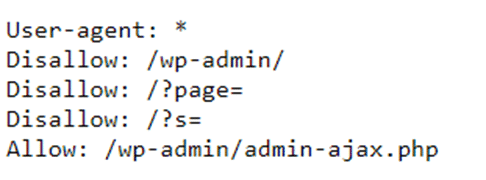
W tym wypadku user-agent jest zakwalifikowany jako „*” – oznacza to, że zestaw dyrektyw dotyczy absolutnie każdego robota. Specjaliści SEO swoje komendy najczęściej kierują do botów Google – to one leżą w kręgu zainteresowania specjalistów SEO, jednak niektóre treści i podstrony nie powinny być odwiedzane przez nikogo oprócz właścicieli strony.
Z kolei dyrektywy zawierające /wp-admin/ dotyczą folderu logowania do panelu WordPressa. Treść ta oznacza, że żaden robot nie może odwiedzać i indeksować podstron WordPressa do logowania. Następnie wyindeksowane są również zasoby, które zawierają takie elementy jak /?page= oraz /?s=.
Wyjątkiem tutaj jest ostatnia reguła, która stoi poniekąd w sprzeczności z wyindeksowaniem panelu logowania WordPressa. Roboty mają zezwolenie na użytkowanie zasobów przesłanych przez plik admin-ajax.php.
Istotną kwestią w budowie pliku robots.txt jest to, że roboty przetwarzają plik z góry na dół, a jeden zestaw reguł odnosi się tylko do określonego robota (lub każdego, jeśli jest znak „*”).
Dodatkowo należy zwrócić baczną uwagę na wielkość liter – Semahead i semahead to nie jest to samo. Ponadto znak # oznacza początek komentarza. Jeśli umieszczamy coś w linijce po „#”, nie będzie to rozpatrywane przez żadnego bota – to informacja np. dla developerów bądź osób zarządzających stroną, by np. w przyszłości wiedzieć, dlaczego coś zostało zablokowane. Podczas przetwarzania komentarze są ignorowane.
Google Bot – Googlebot/2.1
User-agent: Googlebot-News,
User-agent: AdsBot-Google,
User-agent: Mediapartners-Google (Google Adsense).
User-agent: Google-Read-Aloud
User-agent: Google-Site-Verification
Plik robots.txt to bardzo istotny element zwłaszcza dużych witryn. O ile na mniejszych stronach, na których jest niewiele podstron, budżet indeksowania jest zawsze podobny, o tyle w przypadku dużych stron każdy grosz przeznaczony na indeksowanie się liczy. Jeśli serwis jest naprawdę duży i skomplikowany, zawiera liczne podstrony, których nikt by się nawet nie spodziewał, to sprawne nawigowanie robotem indeksowania jest niezbędne. Skanowanie naprawdę dużego serwisu może zająć tygodnie a nawet miesiące. Sprawa się wydłuża, gdy mamy w serwisie podstrony, których roboty Google wcale nie muszą indeksować, a jednak to robią, ponieważ nie mają wyraźniej komendy, by tego nie robić.
„A po co mi ten robots.txt potrzebny” – myśli sobie właściciel strony, który nie chce nic blokować. Dlatego wiele osób stwierdza, że nie będzie implementowało strony, która nie przyniesie żadnych realnych korzyści. To błąd! Wystarczą nawet dwie linijki brzmiące jak poniżej:
User-agent: *
Allow: /
Lepiej by cokolwiek było pod tym adresem, aniżeli miałaby pojawić się strona błędu 404. Taki błąd już na samym wejściu może sprawić, że z roboty będą z mniejszym entuzjazmem crawlować naszą domenę. Jak zostało wspomniane powyżej, ten plik jest pierwszym punktem styku robotów z domeną – warto by nie był to błąd 404.
Najprostszą opcją jest wykorzystanie testera pliku robots.txt – dostępny jest on tylko wówczas, gdy mamy zweryfikowany profil w Google Search Console. Wtedy możliwe jest np. sprawdzenie, jak na domenę wpłyną bardzo konkretne zmiany w strukturze dyrektyw, dodanie bądź usunięcie poszczególnych komend. Jest to bardzo przydatne podczas działania ze skomplikowaną materią struktury dużych serwisów. Z testera można skorzystać tutaj: https://support.google.com/webmasters/answer/6062598?hl=pl.
Osoby z zapleczem programistycznym mogą również sprawdzić bibliotekę Google typu open source z zasobami dotyczącymi pliku robots.txt, która jest też używana w wyszukiwarce Google. Pozwala ona na lokalne testowanie plików robots.txt.
Plik robots.txt jest bardzo ważny w strategii zarządzania budżetem indeksowania danej witryny. Nieodzowny jest również w przypadku dużych serwisów zawierających wiele rozmaitych podstron, które niekoniecznie powinny być odwiedzane przez rozmaite boty. Przejmijmy stery i zarządźmy ruchem robotów Google na naszej stronie!


Chcesz zacząć współpracę z nami? Wypełnij formularz!
Wypełnienie zajmie Ci kilka chwil a nam pozwoli
lepiej przygotować się do rozmowy z Tobą.
